- Published on
Front-End Parallelizable Tasks Using The GPU
- Authors

- Name
- Rob Sutcliffe
- @firefields
TL;DR
- Parallelisation has become a common design pattern as network speeds have increased at a faster rate than CPU clock speeds.
- Developers should work within
The Principle of Known Reliability: We should run tasks on hardware with known characteristics. - There are multiple benefits to running large computations on a client machine. e.g. security, cost and speed.
- GPUs can be used for running consecutive concurrent computations.
- We can benchmark
The GPU Crossover Threshold pointto work withinThe Principle of Known Reliability.
Why we run parallel computational tasks on a client machine?
A simple heuristic is that we should run computational tasks on a server and only run I/O tasks on a client machine.
If for no other reason than for an unnamed principle, we should work on a component with known characteristics. I'm calling this The Principle of Known Reliability. We need to find out what machine our user has and what other tasks it's running. We know what's running on our server and have load balancers to ensure it's not overloaded.
In recent years, we've seen some server-side tasks written in JavaScript (node.js) to handle the I/O tasks that have to be run on a server. We do this because JavaScript is optimised for I/O. But what about when we run computational tasks on the client machine?
There are a few reasons we may choose to run computations on a client machine:
Security: We might have data we want to stay on the client's machine.
Cost: We aren't provisioning a distributed server with multiple high-end CPUs; if we are, we may not need to run them as often.
Speed: If we can work within
The Principle of Known Reliability, it might be faster to work on the client. Especially when security concerns might ass in an SSH handshake or costs might mean we didn't get the best CPUs available.
We already run concurrent computations on our GPU all the time. We run vast numbers of concurrent computations on our GPU. Video encoding or geometric calculations for 3d animations. Writing fragments to run computations on the GPU has become more accessible thanks to libraries like GPU.JS.
But can we use it to distribute front-end tasks, and how does it compare? Why would we want to? Can we achieve this without breaking The Principle of Known Reliability?
How to benchmark execution times to assess when to use the GPU?
Using The Matrix Multiplication Example from the GPU.JS website, I ran several concurrent computations on my CPU and GPU. I then tracked the execution times.
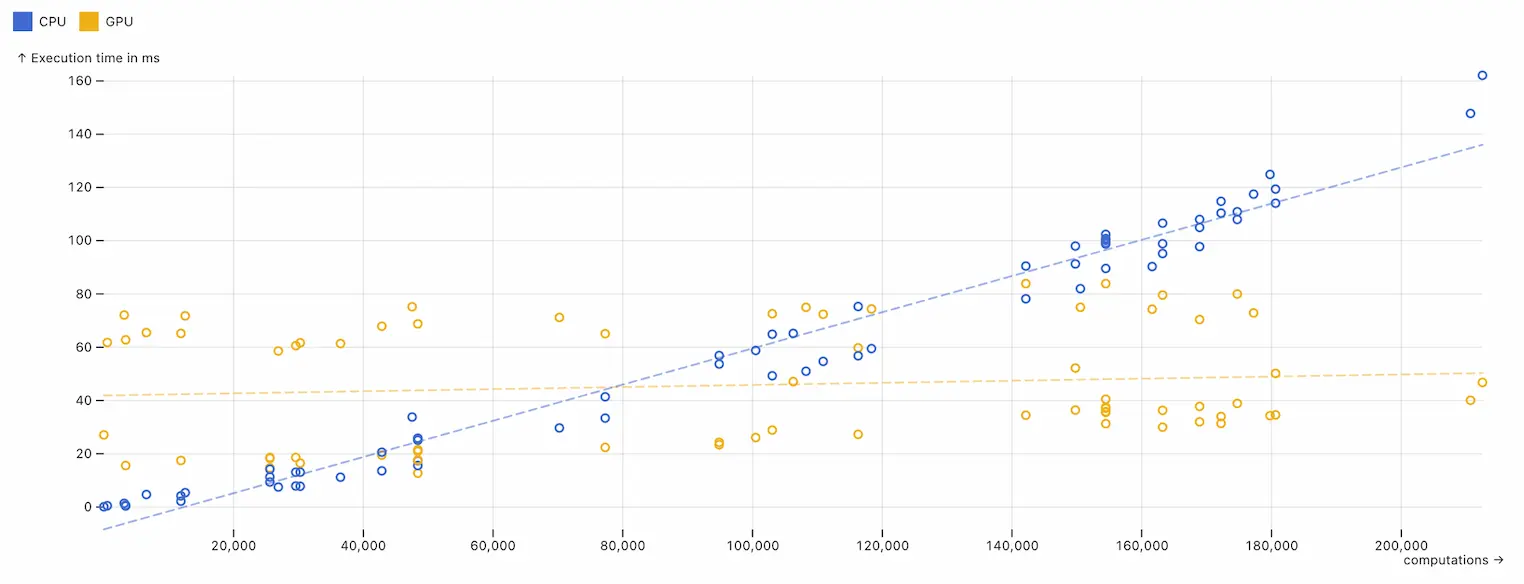
My first observation was that the CPU performs better at executing tens of thousands of computations before it becomes optimal to use the GPU. Several other people have made a similar observation.
Once we get above half a million computations, my CPU can't handle it. My GPU could efficiently run tens of millions of computations before I started running into issues.
The most exciting observation was that the point where running computations on the GPU on my machine was around 80,000 computations. And that I can consistently identify this point after running at most 8 benchmark tests.
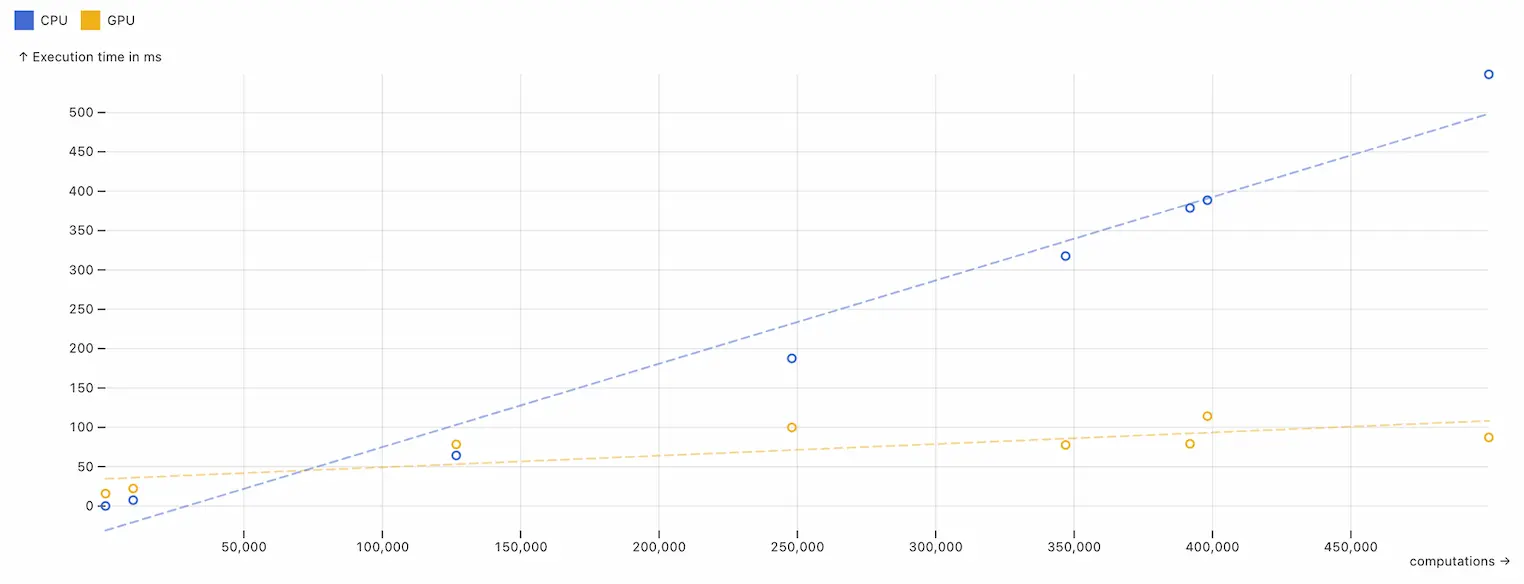
It only takes around 3 seconds for me to identify exactly where the sweet spot is, and this was not affected too much by other processes on the CPU or GPU. I call this point The GPU Crossover Threshold
A Practical Application
Below is a hypothetical scenario.
An investment firm is conducting risk assessments on an extensive portfolio of assets. The assets are sensitive and contain confidential information. The firm uses an application to run concurrent Monte Carlo simulations. They then use these simulations to model various market scenarios and their impact on the market.
These computations need to run on a client machine because:
The data is sensitive, and there are strict rules about where and how the data is shared for compliance reasons.
They need real-time decision-making. Relying on server connections will induce latency issues.
One of their justifications for running the computations on a client machine is real-time decision-making. Anything they can do to reduce this latency is an advantage to our hypothetical firm.
If I worked at this firm and ran this on my computer according to my manual benchmarking, I would use my CPU when I run less than 80,000 computations and run computations on my GPU for over 80,000. But other employees' machines and their specific processes might have a different GPU Crossover Threshold.
My proposal to the developers of the imaginary application used by the investment fund would be this: Run eight background benchmark tests every hour to identify the GPU Crossover Threshold of the client machine. Then, use The GPU Crossover Threshold to dictate when a collection of simulations is modelled on the client's CPU or GPU.